Let’s clear the hype: Machine Learning (ML) is not magic. It’s a rigorous, mathematically grounded discipline for building systems that improve their performance at a task through exposure to data. This past paper is your crucible—it tests whether you can move beyond being a user of ML libraries to being a practitioner who understands the models, the math behind them, the trade-offs in choosing them, and the profound responsibility of deploying them.
Forget black boxes. This is about peering inside the learning machine, tuning its gears, and diagnosing why it succeeds or fails. It’s the engineering of statistical inference and optimization.
What This Paper Actually Learns: Your Mastery of the Learning Pipeline
1. The Foundational Trinity: Data, Model, and Loss
Every ML problem rests on three pillars, and the exam tests your command of each:
- Data: Understanding features, labels, training/test splits, and the curse of dimensionality. You’ll be asked to preprocess data: handle missing values, normalize features, or engineer new ones.
- Model: The mathematical function or structure to be learned. You must know the families.
- Loss Function: The measure of “wrongness.” You’ll justify the choice of loss: Mean Squared Error (MSE) for regression, Cross-Entropy for classification.
2. The Core Paradigms: How Learning Happens
The paper demands fluency in the three main learning frameworks.
A. Supervised Learning: Learning from Labeled Examples
- Regression: Predicting continuous values. Linear Regression is your baseline. You’ll derive the normal equations, implement gradient descent, and understand regularization (Ridge/Lasso) to combat overfitting.
- Classification: Predicting categories. You’ll master:
- Logistic Regression: Despite its name, a linear classifier. You’ll derive its loss from MLE principles.
- Support Vector Machines (SVMs): The max-margin classifier. You’ll understand the kernel trick to handle non-linear data without explicitly transforming features.
- Decision Trees & Random Forests: Interpretable, non-linear models. You’ll calculate information gain or Gini impurity for splits and explain the power of ensemble methods like bagging (Random Forests) and boosting (Gradient Boosting Machines, XGBoost).
B. Unsupervised Learning: Finding Structure in the Wild
- Clustering: Grouping similar data. K-Means (with its sensitivity to initialization and the elbow method for choosing *k*) and Hierarchical Clustering.
- Dimensionality Reduction: Principal Component Analysis (PCA). You’ll be able to explain it as finding the directions of maximal variance and use it for visualization and de-noising.
C. Reinforcement Learning (RL): Learning from Interaction
While often a dedicated course, papers may cover basics: an agent in an environment taking actions to maximize cumulative reward. You’ll understand the trade-off between exploration and exploitation.
3. The Engine: Optimization and Evaluation
Knowing models is useless without knowing how to train and judge them.
- Optimization: Gradient Descent and its variants (Stochastic, Mini-batch). You’ll understand learning rates, convergence, and the role of derivatives.
- Evaluation Metrics: Precision, Recall, F1-Score, ROC-AUC curve for classification. R², RMSE for regression. You’ll interpret these to diagnose model performance (e.g., “high precision, low recall means the model is conservative”).
4. The Neural Network Revolution: A Deep Dive
A significant portion will be dedicated to Deep Learning.
- Neural Network Fundamentals: Architecture (input/hidden/output layers), activation functions (ReLU, Sigmoid, Softmax), the chain rule, and backpropagation. You’ll perform a forward and backward pass for a small network.
- Convolutional Neural Networks (CNNs): The architecture for images. You’ll explain convolutional layers, pooling, and feature hierarchies.
- Practicalities: Overfitting and how to combat it with dropout, batch normalization, and data augmentation. The importance of hyperparameter tuning.
5. The Critical Overlay: Ethics and Best Practices
Modern ML exams test your conscience as much as your calculus.
- Bias & Fairness: How historical bias in data leads to discriminatory models. You’ll discuss fairness metrics (demographic parity, equalized odds).
- Explainability: The need for interpretable models (LIME, SHAP) versus the “black box” problem of deep learning.
The Paper’s Ultimate Challenge: The End-to-End Case Study
The hardest question will drop you into a real-world scenario:
“You are given a dataset of patient medical records to predict disease risk. The data is imbalanced (5% positive cases) and has mixed data types (continuous lab results, categorical demographics).
- a) Propose two different model families suitable for this problem and justify your choice for each.
- b) For one model, describe your precise steps for data preprocessing and addressing class imbalance.
- c) How would you evaluate your model’s performance, and which metric would you prioritize for clinical deployment and why?
- d) Discuss one major ethical consideration in deploying this model.”
This tests every stage of the ML pipeline: problem framing, data wrangling, model selection, evaluation, and ethics.
How to Master This Past Paper:
- Think in Terms of Bias-Variance Trade-off. This is the central concept of ML. Can you diagnose if a model is underfitting (high bias) or overfitting (high variance) and know the remedy for each?
- Derive, Don’t Just Memorize. Be able to derive the gradient of the loss for Linear/Logistic Regression. Understanding the “why” of the math makes the “how” of implementation trivial.
- Practice “Sketching” Models. Quickly draw the architecture of a 2-layer NN, a decision tree, or the mapping performed by an SVM with an RBF kernel. Visual intuition is key.
- Code on Paper. Practice writing clean pseudocode for key algorithms (gradient descent, K-Means). Syntax isn’t graded; clear logic is.
- Connect Theory to Real-World Behavior. Why does ReLU help with vanishing gradients? Why does Lasso regularization lead to sparse models? These “why” questions are the heart of the exam.
This past paper is your license to learn. It certifies that you have moved from treating ML as a toolkit of functions to understanding it as a principled, powerful, and perilous framework for building intelligent systems. Passing it means you are ready to build models that don’t just run, but reliably generalize—and to do so with ethical foresight.
Machine learning all previous/ past question papers
Q1: A model has been tested and the following model evaluation measures are observed. Calculate the MSE and MAE and which one is better for this dataset?
| Y(Actual) | Y’(Predicted) |
| 10.2 | 9.4 |
| 3.5 | 1.7 |
| 7.1 | 6.9 |
| 14.5 | 15.4 |
| 17.2 | 18.4 |
| 41.5 | 17.2 |
| 2.7 | 2.5 |
| 11.5 | 11.1 |
| 5.9 | 6.7 |
| 15.3 | 15.2 |
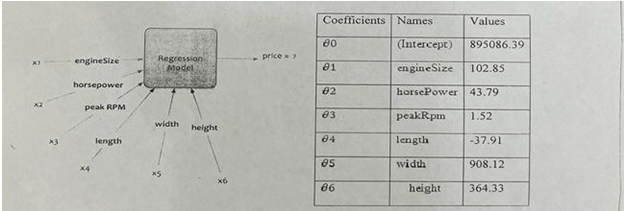
Q2: If engine Size = 130, horsepower= 111, PeakRpm = 5000, Length = 16, Width = 6, Height = 13, Calculate the price of car and write the model name which is suitable for this example?
Q3: By using the following cost function of gradient descent, derive the equation for third co-effient?
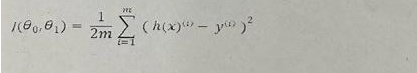
Q4: An OLS model is trained on the dataset and the following results are stated in the table. Calculate the R2 from the following table? What does that R-squared value mean?
| y-actual | Y-Predicted |
| 700 | 782.3275862 |
| 900 | 977.5862069 |
| 1300 | 1172.844828 |
| 1750 | 1563.352069 |
| 1800 | 1953.87931 |