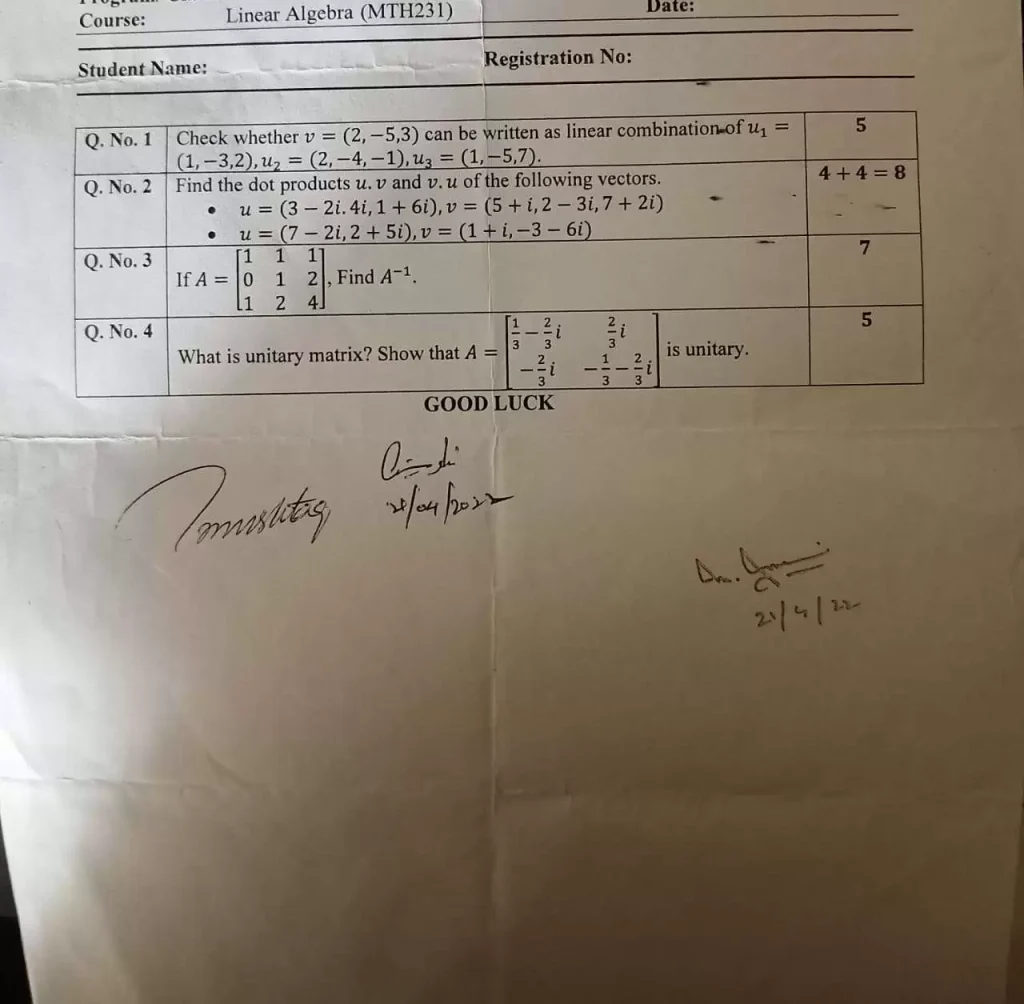
Let’s get this straight: Linear Algebra is not a class about solving tedious systems of equations. It is the fundamental language of data, geometry, and transformation in the digital world. This past paper is your test of fluency in that language. It asks: Can you see vectors and matrices not as grids of numbers, but as powerful, abstract objects that manipulate space, compress images, train AI, and render 3D graphics?
Forget rote calculation. This is about understanding structure, space, and transformation. It’s the math behind the magic.
What This Paper Actually Computes: Your Geometric and Algebraic Intuition
1. The Atoms: Vectors and Spaces
The foundation is shifting from thinking about numbers to thinking about objects in space.
- Vectors as Data: A vector isn’t just (x, y). It’s a point in space, a direction, a force, a data sample (e.g., a user’s ratings for 100 movies is a 100-dimensional vector).
- Vector Spaces & Subspaces: The playground where all vectors live. You’ll need to check if a set of vectors forms a subspace—are they closed under addition and scalar multiplication? Key subspaces: Column Space and Null Space of a matrix.
- Linear Independence, Span, Basis: The vocabulary of constructing spaces. Can a set of vectors build every other vector in the space (span)? Are there any redundancies among them (independence)? A basis is a minimal, efficient set of “building block” vectors for a space. You’ll find bases and understand dimension.
2. The Transformers: Matrices as Functions
This is the core conceptual leap. A matrix is a linear transformation.
- Matrix-Vector Multiplication (Ax): Not just a procedure. It’s the act of transforming the vector
x—rotating it, stretching it, projecting it, or collapsing it—into a new vectorb. - Solving Ax = b: You’re asking: “What input vector
x, when transformed byA, gives me the outputb?” You’ll solve systems using Gaussian Elimination and understand the geometry: the solution is the intersection of lines/planes/hyperplanes. - Matrix Multiplication as Composition: Multiplying matrices
ABmeans applying transformationB, then transformationA. Order matters.
3. The Deep Structure: Decomposition and Insight
This is where linear algebra reveals its true power—taking a messy matrix and breaking it into interpretable, fundamental pieces.
A. Eigenvalues and Eigenvectors: The “DNA” of a matrix.
- An eigenvector is a special direction that, when transformed by
A, only gets stretched or shrunk (by the eigenvalue), not knocked off its axis. - Why it matters: They reveal the stable, fundamental modes of a system. Used in:
- Principal Component Analysis (PCA): Finding the directions of maximum variance in data (the eigenvectors of the covariance matrix).
- PageRank: The core of Google’s original algorithm (finding the dominant eigenvector of the web graph).
- Stability analysis of systems.
B. Matrix Factorizations: The ultimate toolset.
- LU Decomposition:
A = LU. Breaks a matrix into a lower and upper triangular matrix. This is Gaussian Elimination made permanent, optimizing repeated solves. - QR Decomposition:
A = QR. Orthogonalizes the columns ofA. Crucial for solving least-squares problems (fitting lines to data). - Singular Value Decomposition (SVD): The “crown jewel.”
A = UΣVᵀ. Decomposes any matrix into rotation-stretch-rotation.- Applications are everywhere: Image compression (keeping the large singular values), recommendation systems (collaborative filtering), latent semantic analysis in NLP.
4. The Geometry: Orthogonality, Projections, and Least Squares
- Dot Products & Orthogonality: Measures similarity and angles.
xᵀy = 0means perpendicular. - Projections: Finding the closest point in a subspace to a given vector. This is the heart of least-squares regression—finding the line that best fits noisy data, even when
Ax=bhas no exact solution. - Orthogonal Matrices: Matrices that preserve lengths and angles (rotations and reflections). Their inverse is their transpose (
QᵀQ = I).
5. The CS Connection: It’s Everywhere
You must be able to articulate why this matters:
- Computer Graphics: Every 3D rotation, translation, and scaling is a matrix multiplication.
- Machine Learning: Data is a matrix (samples × features). Training a model is often an optimization over a high-dimensional vector space.
- Data Science: Dimensionality reduction (PCA = SVD), clustering.
- Network Analysis: The web, social networks—represented as adjacency matrices. Eigenvectors reveal central nodes.
The Paper’s Ultimate Challenge: The Interpretive Problem
The hardest questions won’t ask for mere calculation. They will say:
*”The matrix A has eigenvalues 3, 3, and -1. What can you say about its determinant, trace, and invertibility? If one eigenvector for λ=3 is [1,1,0] and for λ=-1 is [0,0,1], describe geometrically what the transformation A does to the xy-plane and the z-axis. Is A diagonalizable? Justify.”*
This tests deep synthesis of properties, geometry, and theory.
How to Conquer This Past Paper:
- Visualize, Visualize, Visualize. For 2D and 3D, draw the vectors! See a matrix as something that squishes, rotates, or reflects the whole grid. This geometric intuition is priceless.
- Understand the “Four Fundamental Subspaces.” For any matrix
A, know the Column Space C(A) (all possible outputs), Null Space N(A) (inputs that get crushed to zero), and their orthogonal counterpartsC(Aᵀ)andN(Aᵀ). This framework organizes half the subject. - Master the Conceptual Definitions. Don’t just memorize steps for finding eigenvalues. Understand they are the
λfor which(A - λI)is singular (has a non-zero nullspace). Connect concepts. - Practice with Purpose, Not Mindless Calculation. When doing elimination, think: “I’m performing row operations that are left-multiplying by invertible matrices, which doesn’t change the solution set.” Understand the why of each step.
- Link to Applications. When you learn a decomposition, immediately ask: “What is this used for?” (LU for solving equations fast, QR for orthogonalization, SVD for compression). This cements understanding.
This past paper is your proof of multidimensional literacy. It certifies that you can think in high dimensions, manipulate abstract spaces, and wield the single most important mathematical toolkit in modern computing. Passing it means you’re ready to speak the native language of data.
Linear algebra Sessional I Question paper

Linear algebra Sessional 2 Question paper

Linear algebra Final Question paper